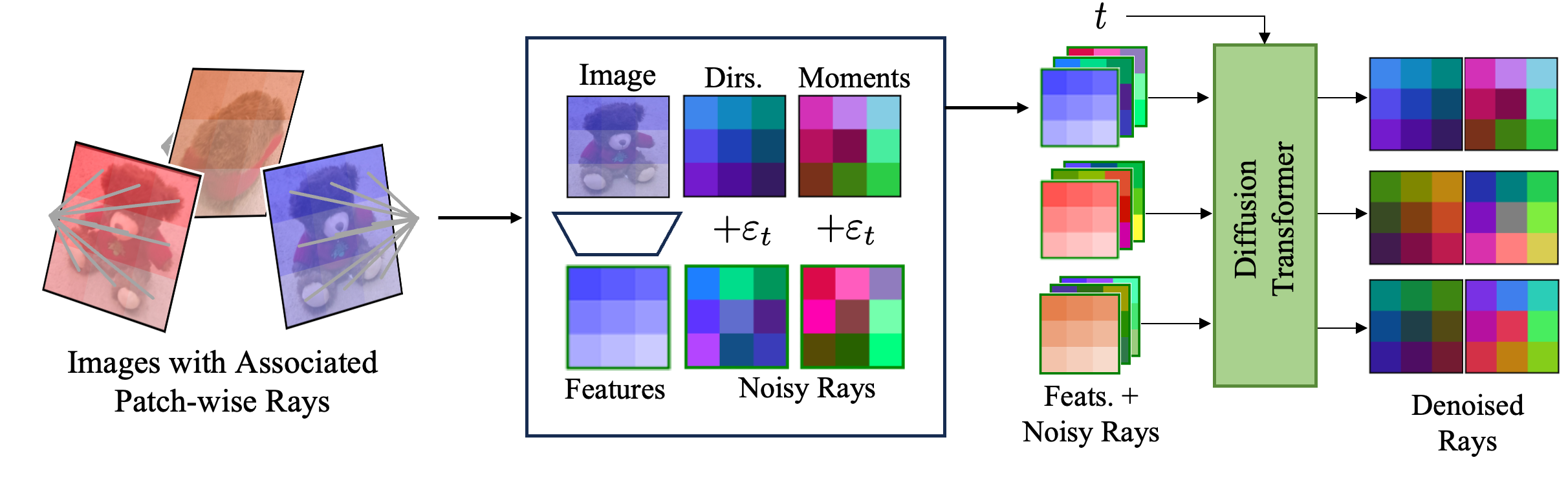
Recovering Wide-baseline Camera Parameters by Denoising Rays.
Conditioned on several
sparsely sampled views of an object, our approach learns to denoise a set of
camera rays, parameterized using 6D Plucker coordinates consisting of 3D ray
moments and 3D ray directions. Here, we visualize the backward diffusion
process, denoising from randomly initialized rays. We then recover camera
intrinsics and extrinsics from the positions of the rays using least-squares
optimization.
Abstract
Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparse views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
Paper
Cameras as Rays: Pose Estimation via Ray Diffusion
Jason Y. Zhang*, Amy Lin*, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, and Shubham Tulsiani
@InProceedings{zhang2024raydiffusion,
title={Cameras as Rays: Pose Estimation via Ray Diffusion},
author={Zhang, Jason Y and Lin, Amy and Kumar, Moneish and Yang, Tzu-Hsuan and Ramanan, Deva and Tulsiani, Shubham},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
This work was supported in part by the NSF GFRP (Grant No. DGE1745016), a CISCO gift award, and the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/Interior Business Center (DOI/IBC) contract number 140D0423C0074. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon.
Webpage template.