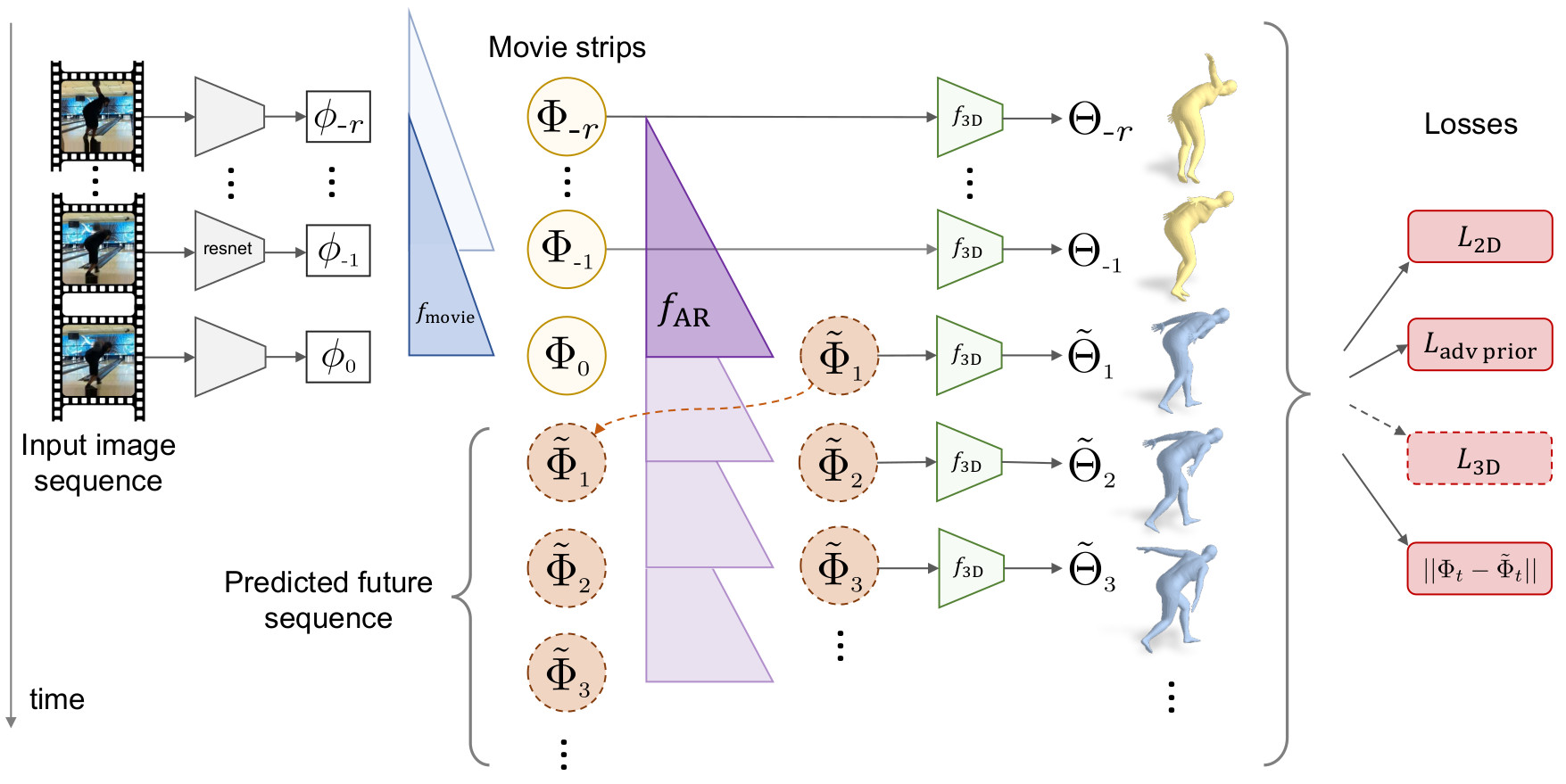
Predicting 3D Human Dynamics from Video
Jason Zhang, Panna Felsen, Angjoo Kanazawa, and Jitendra Malik
@InProceedings{zhang2019phd,
title = {Predicting 3D Human Dynamics from Video},
author = {Zhang, Jason Y. and Felsen, Panna and Kanazawa, Angjoo and Malik, Jitendra},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
year = {2019},
}