Abstract
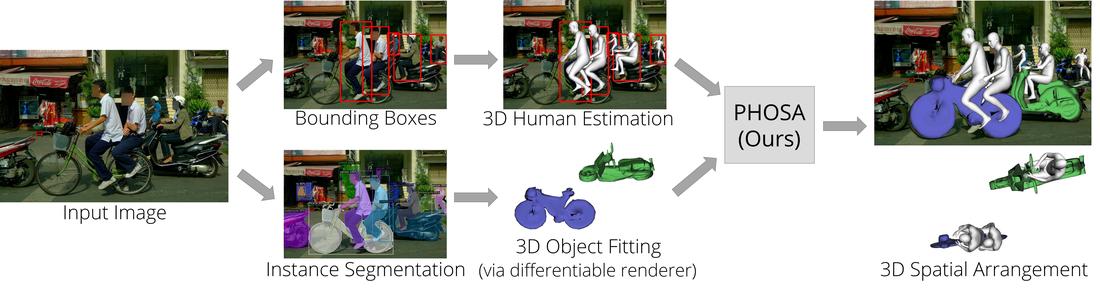
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively unexplored domain.
Paper

Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Jason Y. Zhang*, Sam Pepose*, Hanbyul Joo, Deva Ramanan, Jitendra Malik, and Angjoo Kanazawa
@InProceedings{zhang2020phosa,
title = {Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild},
author = {Zhang, Jason Y. and Pepose, Sam and Joo, Hanbyul and Ramanan, Deva and Malik, Jitendra and Kanazawa, Angjoo},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020},
}